The only thing the world never changes is that everything changes – by Heraclitus
Motivation of writing this article
Modern AI driven companies suffer from Human Resource Management because AI is not even meant to be Labor Intensive Industry but Intelligence Intensive one.
现代AI驱动的公司遭遇着人力资源管理的沉重负担,不仅仅因为AI本身意味着解放劳动力(人力资源密集型产业),意味着智力密集型产业。
Optimization for whole pipeline of data processing, -- ranging from data acquisition, data consuming(Machine Learning for models construction, Distributed Computing for Big Data), data storage(storage and randomly fast accessing for big data), data visualization--, systemantically, goes far away from the fact that expenditure of such optimization used only for in-groups purpose whithin companies can be too great for entrepreneurs or VP to make decision to do it.
They hereby are more cautious about “technology selection” to use better technology (equivalently baseing hope on success from outside). While, in contrast, if such effort has already been made, we must share it to entities outside as a marketing strategy to make greater values.
Tensorflow, for example, popular all over the world in a few months, offically published in 2015 November, 2015, Google Research, push Goolge on the top of “AI companies”. The high yield comes from fast growing number of google developers and products.
Lei’s one year long term survey from 2016 to 2017 in Peking China, more than 100 companies survey, can support his argument, while not well understood by some people:
针对于整个过程的系统地优化,其本身,-- 从数据的获取,数据消化(比如机器学习中模型,以及大数据技术中的分布式计算技术MapReduce等,数据存贮 (比如大数据技术中分布式存贮技术对象存贮等和随机访问), 数据的可视化--,远远和实际工作不符合。实际上,这种公司内部的优化极大的消化人力成本和公司寄托于于业务的机会成本,以至于对于相当数量的企业家或者高级经理人VP等,没有勇气拍板做出决定去放手开发,从而使他们对技术选型更加谨慎,寄托于使用更加优良的开源技术 (或者准确地说寄托于别人的成功) 来解决这些问题。
Tensorflow,就是一个成功的产品,在短短数月,全世界流行开来,帮助谷歌成为最备受欢迎的ML技术领导的企业。相反,若果公司战略管理层,决定了,采取针对智力密集型工作的大规模优化任务,必然会寄托于转让,开放给外部企业法人,机构等 的销售策略,实现更大化的战略赢利。这是内在逻辑所决定的。
Lei的一年长期调查访谈,从2016年到2017年,在中国北京地区的实地调查,可以支撑他的以下, 但却被不少人所不了解的观点(欢迎一起和我讨论这个问题):
Machine Learning as Service can only work in cloud based company; if they are not, they will eventually become cloud based company
机器学习可能会在云计算公司取得最终的成功;如果他们不是云计算公司,他们终将会变成云计算公司
We will anaylize the argument based on my research in three steps in this section and then quickly jump to our main course Technical Analysis. This series of articles targeted on professionals working on this field.
In Section 1.1 Machine Learning in Entities, we discuss how does machine learning work in companies and the way they are organized. In Section 1.2 Successful Stories for ‘“MLAS” does not work’, we summaries why MLAS “does not work” in some people’s viewpoint and successful stories of Non-MLAS. In Section 1.3 ML R&D engineers’s problems, we discuss a simple optimziation problem I proposed in Sep 2017 in team discussion, and problems to prevent ML Senior R&D engineers from making it into realities.
我们将会从基于调研的三个层面,分析“论断”,然后快速跳跃到我们的主菜“技术分析”. 本系列文章目标人群是从事ML的专业人士。
在1.1 小节,机构中的机器学习,我们讨论了通常机器学习是如何支撑公司的业务,和典型的公司部门组织方式(区别于上课的企业组织的课程所涉及的内容)。在1.2 小节,MLAS为什么“不成功”以及“非MLAS”的成功案例,我们总结了“MLAS不成功的原因”. 在1.3 小节,机器学习R&D工程师的困境,我们从一个简单的问题来分析ML R&D 高级工程师们由于普遍受自己的专业知识,业务所限制,解决该问题的困难。
The rest of the series will consist of technical analysis and be organised as following:
- Introdcution: we will briefly introduce tensorflow and OCI standard, then propose questions we will work on.
- What affects ML most? I am Serious.
- A Simple Strategy Based Model Price-Discount Prediction: how do stategy developers work daily
- What ML learns: Error analysis
- Do you understand “Bias”?
- Why “Bias” cannot work in a general model: system error from a small portion of data
- general approach framework & examples
- Why you should learn multiple metrics not ones taught in CS ML course: You need to learn a lot of mathematics, I mean it.
- Work with Architecture Group, BI, Operation, VP and so on.
- Mathematicians Do Not work, in some extend to which companies care about.
- Tiny Distributed Tensorflow: we disscuss techniqes and possible solutions we need to create a tiny tensorflow from scratch.
- Achitecture of Distributed Tensor flow
- Computing Graph
- Abstract Syntax Tree
- A Simple Question on Graph partition
- Duplicated Operation Elimination
- Model Partition and communication
- Data replica: from MapReduce to OCI
- MapReduce recall
- Implementation in Tensorflow
- General thinking, from MSR paper
- model replica: Give you a wighted tree and N servers, please code a simple programe to distribute the tree components with evenly cost
- OCI standard & Docker application for tensorflow
- Who are Cloud infrastructure developers?
- OCI standard
- Deploy tensorflow Clusters in a Private Cloud.
- Related materials
- Conclusion
- Future work & expectation
- Acknowledgements
- Reference & Bibliography
系列文章剩下的部分将按以下方式组织:
- 介绍:我们将简要地,基于文献检索介绍tensorflow和OCI标准。 然后,我们提出本文研究的问题。
- 什么会影响机器学习?我是认真的
- 一个简单的策略模型,价格折扣预测: 策略工程师如何工作的?
- ML会学习什么呢:误差分析
- 您真的了解模型中的”bias”吗?(很多讲师在这里比较仓促)
- 为什么”bias”不起作用:小样本范围内的系统误差
- 一般方法框架和案例
- 为什么您应当学习更多的 测度 而不仅仅是CS系里面的ML教书告诉您们的一些:您确实需要学习很多数学
- 和架构组,BI,运营,决策层一起工作
- 从公司的某种角度,数学家不管用的
- “小型分布式Tensorflow”:常用的技术,想象下,假如我们需要从头搭建一个简易分布式tensorflow
- 整体架构
- Suported Devices & Replica types
- Tensorflow-Serving
- gRPC protocle
- 计算图
- 抽象语法树
- 一个简单的图划分问题
- 重复计算消去术
- 模型划分和通信
- 数据并行:从 MapReduce 到 OCI
- MapReduce回顾
- 在Tensorflow中实现数据并行
- 一般性思考,MSR的论文
- 模型并行:给你一棵带边权的树,N个服务器,请写一个简单的算法,实现将树的联通区间划分,使得每个联通区间的权重近似均匀
- 整体架构
- OCI标准和tensorflow在docker中的应用
- 开发云的都是那些人?
- OCI标准
- 将tensorflow集群部署在私有云上
- Map-Reduce framework
- 相关的工作
- 结论
- 未来的工作
- 致谢
- 参考文献
Machine Learning in Entities
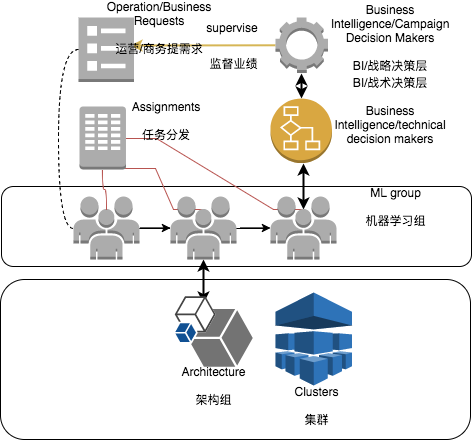
Thanks to Mr Chen, and other leaders in industries. Talking with them, I hereby obtain some information which I am not able to get from my working experience. For AI industry, I have the following judgement:
- Operation dirven: as figure organization illustrates, we establish a high efficently ML driven Operation closed loop. Here are three ML examples to support it:
- Logistic Regression (We use svm INSTEAD if ‘good’ samples predominate and the total samples used are not necessarily large): the model can learn parameters w1=10, w2=100, w3=-10, w4=-1000… BI then report to managers that feature A has strong positive effect, while feature B has strong negitive effect. Finally, our managers command Operation Group to enhance the operation 1, while decrease operation 2
- Extremely Gradient Boosting Decision Tree(exGBDT): the model verifies that feature 12 in decision tree visited by 1000 times! BI then report to VP; VP make decision to make business with VM officers that we can provide you with a lot of valuable data to help you sell cars!
- Deep learning: While we have a good model, but nothing to report because too much layers and downpours involved!
- Concrete ML problems: ML is studying a mapping F: X -> Y. In the most cases, we want to obtain a mapping F with high preceion and resolution so that we can analyze the problem in multi sacles. The following subjects give problems have been kept studying by people deeply:
- Computing Advertisedment & Recommend systems: deep embeded in system logics
- NLP: word embedding, natural language syntax tree, conversation understanding …
- Image recognition: searching images by images, autonouse vihicles information fusion system
- Speech Recognition
- fast searching: learning to hash
- High Performance Computing
{kind=link}
首先感谢陈雨强先生,等行业领头人,因为和他们对话,使我获得了与从业资历并不对等的知识和经验,而通过交叉验证,使我初步形成判断,非常感谢。ML在企业大致有以下格局:
- 运营驱动:通过ML驱动业务,形成高效的如图Organiztion的运营反馈闭环. ML模型即通过埋点等点数据收据收集方式,甚至大规模数据收集方式来推测某种业务和业务目标的关系,此类业务往往需要解释性比较强的模型。在现行体系下,较少有团队使用深度学习。举三个例子予以说明:
- Logistic Regression (若样本比较少,由于SVM仅仅依赖错误数据分布,数据表现比较好时候会代替lr): ml组会学习到参数w1=10, w2=100, w3=-10, w4=-1000…,BI组获得此数据立刻分析出w2所对应原始特征(用关联分析法)有较强的 正反馈,w4所对应的原始特征有较强的负反馈Dual Problem,立刻上报决策层;决策层指示,运营强化指标1,弱化指标2 reinforcement learning
- Extremely Gradient Boosting Decision Tree(exGBDT): ml组发现决策分支f12被访问了1001次!决策分支f64被访问了10次,立刻上报BI, BI上报VP,埋点15对应的数据效果比较好;VP一拍板,和大众合作,告诉大众,这个数据非常有商业价值;大众商务人员因此和公司展开业务谈判,VP指示运营组围绕埋点15相关数据进一步挖掘进行商业变现。
- deep learning:业务展开若干天后,ml组告诉BI,“我们的模型已经可以很好地模拟出,业务1 和 业务目标1 的关系了;但是,我们虽然可以很好的看出中间层和目标的关系,却暂时根据现有技术无法论证原始数据和目标的关系,因为采用了比较多的连接,和,downpour等技术”。
- 固定问题场景的ML:ML即是学习映射 F:X -> Y, 由于问题的确定性,我们大多数情况希望获得更加准确的F; 以下描述了,已经被深入研究的问题;
- 计算广告计算广告&推荐等系统:ML作为系统的自动化过程。此类业务往往具有,数据稀疏,规模大,用多重技术综合解决是ml曾经并且继续作为解决自动化问题的重点。
- NLP: word embedding,natural language syntax tree, conversation understanding …
- 图片识别:以图搜图,自动驾驶信息融合系统中外部信息和电子机械装置指令的映射关系
- 语音识别技术
- 快速检索:learning to hash
- 高效计算
Yet except from the first one, professionals , experts are everywhere. The first mission also can only be prefect resolved by converting them to the existing problems. The number of people studying on general ML approach is small. To solve such problems, they must rely on a lot of people of background in distributed computing, system development or even web development.
除了第一项,后面都可以在术业专攻的博士专家和历史传承。第一项工作需要将一个未知的问题转换成已知的问题,从而提出求解方案。真正研究ML的人是非常少的,大家都是在各自的领域研究合适的ML方法论。围绕ML所涉及的大数据问题,往往并不是由从事ML研究人员来解决。他们都需要依托于在网络,服务器,分布式计算,等领域沉浸多年的工程人员来予以解决。
悖论:对相当一部分业务人员,很多ML实现技术只有在面试的时候才有机会用到或者日常中很少用到
Successful Stories for ‘“MLAS” does not work’
Coorperations must pay a lot of efforts to imporve ml system. However, for entities they don’t pocess ability to organize ML engineers, they cannot fully understand how their work significates. For example, better than another by 6 percent precision, faster than another by half speed.
优化一个ml的实现需要付出努力。但是对于没有能力组建技术部门的企事业单位,往往无法理解这项工作的价值,并要求全套解决方案;对于有能力组建技术部门的他们可能会自己实现
They eventually face competition under information symmetry, with price reduction.
在这个前提下,相当的AI业务第三方开发商,往往只能深入一组用户业务,并逐步推出自己的云服务,从而逐步扩大。但是他们的云服务,从容器技术角度是受限的。也就是说,如果一开始报着做平台的想法去做,必然会无法获取种子客户从而在巨大的研发成本压力下,胎死腹中。从业务外包的角度,由于不断有第三方加入,注意到甲方并不理解,乙方AI业务放所做的努力(更高的识别率,比友商提高了百分之6;更快的速度,比友商快一倍),从而陷入信息对称竞争,业务面临报价下降风险。
ML R&D engineers’s problems
日常工作中,R&D往往会遇到数据访问慢,共享资源压力大。集群作为一种昂贵的计算资源每天会被大量的使用,不少工程师都选择使用定时器,在夜间执行任务。那么我要重新审视,什么机器学习中的问题,什么事深深影响人效的?2016年的时候,我决定考虑以下问题:
Suppose we have the following problem: there are m groups in a company D; each group has km missions to visit hadoop nm times. Should we have method to reduce every group visiting times?
假定公司D有以下m个项目组,每个组每天有km个任务,需要访问Hadoop集群nm, 每个工程师抱怨访问时间慢,是否有一种方案可以简化以上平均访问时间?
In 2016, I proposed a method and implement a prototype to deal with the above problem:
We have a manager to schedule tasks. Each task has an expected computing time t. The manager checking periodically by excuting the following commands:
If t > threshold, executed immediately otherwise merged with other tasks w.r.t hadoop visiting services. The manager create a reading point like (unit test setup method), then distribute the results to tasks related.
在2016年小组讨论中,我提出一个方案尝试解决上述问题,并实现一个工程原型:
工程师i提交任务ti,需要访问Hadoop集群 {hi},任务Manager收集任务,对于任务预估时间大于 threshold 的任务,执行以下操作:
每隔一段时间,Manager对具有相同访问需求的实验,合并请求,创建公共读取数据的节点,缓存查询结果 (类似单元测试框架中的TestClass setup method) ;然后,分发到有需要求的节点上。通过这种方式,原来对于一个服务器的多次冲击,有可能被显著减少。
This kind of problem is hardly thoroughly discussed both within ML group or Architectures because the development is expensive and unfortunately, most engineers are expensive than devices.
机器学习是针对大数据的处理技术(data consumption),所有模型从算法到实现,是无法绕开“计算”这个概念本身。那么架构组会帮助ML组解决以上问题吗?从收益上看,难以见效,而成本必定是昂贵的。