Introduction
RPC framework deals with both low level network tranportation and hight level task oriented communication. Low level network utitlities (L4) to set up a socket server using “tcp” or “ipc” protocols are defined in the following headers:
#include <netdb.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <unistd.h>
For better UX or simply higher efficiency, we need concurrency. Server concurrency can be implemented using three techniques:
- System IO Multiplexing: In Linux
- Process forking (Limited concurrency ability and separate address spaces. Hence not porpular in practice)
- Threads pool
The first and the third are discussed in this post. Event based Multiplexing in Linux can be referred to “epoll”; while in MacOS, it is known as “kqueue”; and finally in all *nix system, “select” is avaible for system IO multiplexing. But “select” requires a “O(n) line search”, hence not efficient enough for a real network application. In my demo you can clearly see why this happens.
RPC is short for Remote Procedure Calling. It is essential to network communication involving multiple tasks. RPC network package’s low level abstraction grpc C core decouples network in a more sophisticated structure. It is gPRC core which does the dirty work to handle network transportation. In grpc C core(/src/core/lib/iomgr), we have following layers:
- endpoint
- pollset, event: io event descriptors set
- channel
- execution context: collecting data along calling stack.
- scheduler, completion queue and thread model: start polling and prepare threads poll for handling tasks aysnchroneously triggered by event.
- multithreaded atmoic operations
We will extend this definition to multiple services architecture. In the last post, we have already briefly introduced Microservices Architecture (MA). But that restricts logics mostly within L7 level network. This post explores more about L4 level network implementation.
gRPC C core is very differnt from advanced libraries in customer languages like C++, python, go and etc. The libraries provide underlying network transportation services and be exported by surface API.

API can be referned by including grpc api header file and its sibliings in the same directory:
/* in customer codes
* https://github.com/grpc/grpc/blob/master/include/grpc/impl/codegen/grpc_types.h
* https://github.com/grpc/grpc/blob/master/include/grpc/grpc.h
*/
#include <grpc/grpc.h>
GRPC c core can listen to multiple ports. Each listener fd will be added into all the server completion queue’s pollset. Whenever a file descriptor in some pollset becomes ready, one or more poller threads are woke up[4]. GRPC team reported that this achitecture might have caused “Thundering Herd problem” in both server side and client side so it was not perfect. They introduced recently (mid of 2016) “polling_island” to make sure that only one thread woke up with regard to the associated event fd.
We will walk through core libaries logics and analyze how it be used in upper application through surface api. To this end, we will test our theory to build servers under pressure in a presigeous cloud supplier.
Concurrent Service for RPC on different ports
Multiplexing
Multiplexing means a programe in a single process doesn’t need to wait for kernel to return. These techniques are defined in system kernel code base and can be refered by including one of the following headers:
#ifdef UNIX_EVENT
#include <sys/select.h>
#endif /* defined(UNIX_EVENT) */
#ifdef DARWIN_KQUEUE
#include <sys/event.h> // MacOS(Darwin) kqueue; Apple provides a detailed documentation about how to use it. It is a little bit of like "epoll" in modern Linux.
#endif /* defined(MAXOS_EVENT) */
#ifdef LINUX_EPOLL
#include <sys/epoll.h> // Linux >= 2.5.66
/* [Banu](https://banu.com/blog/2/how-to-use-epoll-a-complete-example-in-c/) has a very detailed tutroial on how to use it.
/* For other utilities, feel free to check my own codes in ComputingGraph/network/tcp GitHub.
*/
#endif /* defined(LINUX_EPOLL) */
The above flags can be specified in compiler args with syntax of “-D{MICRO_FLAG}”. Replace {MICOR_FLAG} with the one you want. They differ from one system to the another.
Here is a simple programme introduced to use those utilites to create concurrent servers handling multiple clients requests asynchroneously.
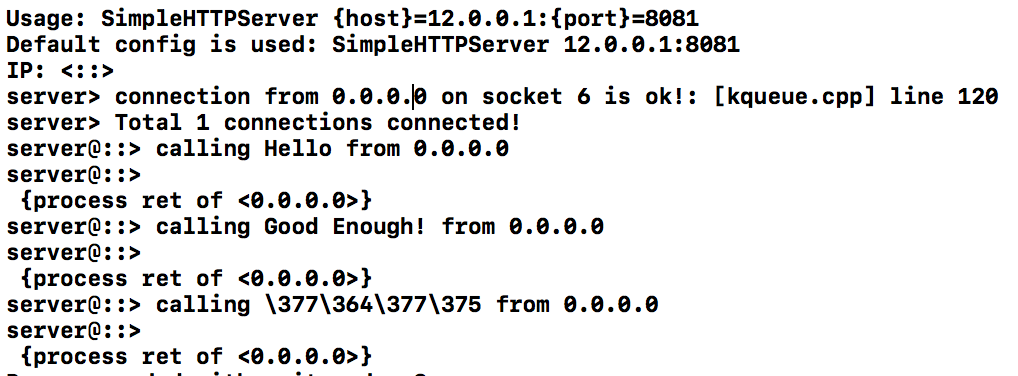
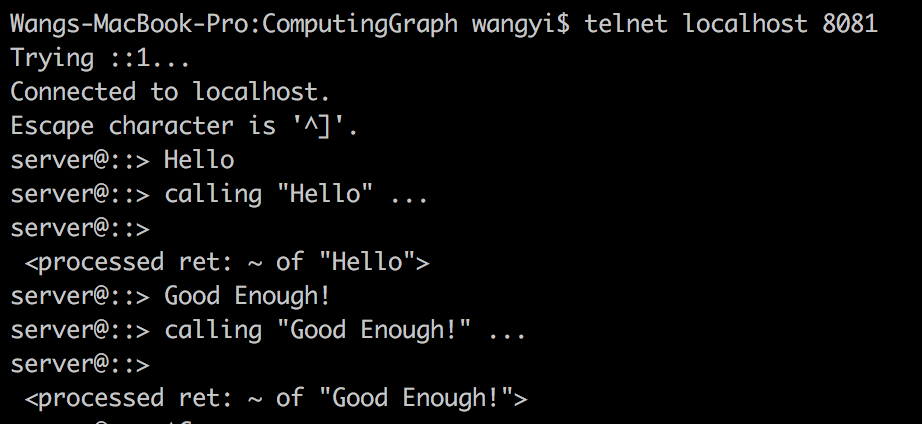
In Micorsoft(MS) platform, a different terminology is employed: I/O Completion Port/Queue. You might rarely hear about it, because this model used by Windows is very differnt:
Notify on completion, i.e I/O requrests notification of completion are issued asynchornously via Completion Queue (CQ)
In GRPC, this part is partially attributed in grpc/core/lib/iocp_windows.cc. Even though we use multiplexing underneath in Linux platform, an event is somewhat like polled by coding a CQ. My focus here is Linux based Concurrent Technology. Someone might argue that MPI is also an alternitive. However, this might not be ture given that MPI is designed for parallel computing. There are some literatures on comparison between different distributed netowrk technologies[1].
Threads pool
#include <pthread.h>
By creating a thread pool in advance, we usually put jobs or clients in a first in first out (FIFO) thread safe queue. Each thread functions as a timmer: a job can be executed immediately or wait until a timmer is counted down to zero. Our implementation should show how this will be dealt with.
Combine them together
The combination allows maximum explioting concurrency capabilities of a machine. The procedures are divided into stages.
First optionally to check your OS, to make sure that you identify the the services provided by kernel before passing flags to a compiler and that local network is in comfortable circumstances. Second, setup a server socket, and add the file descriptor to the event set. Use a idle loop (hung up by kernel programmes) to check whether events are ready. If they are ready, check the event type and dispatch corresponding handlers to a running thread.
// "grpc/src/core/lib/iomgr/tcp_server_posix.c"
A Single Service Achitecture
endpoint
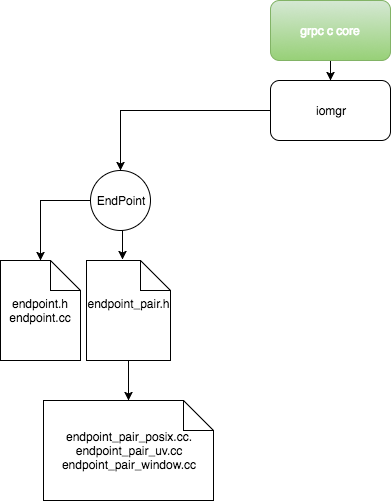
endpoint: By definition, endpoint is a “streaming channel between two communicating processes: tcp socket or UNIX IPC methods like pipes, shared memory and so on”.
In *nix, a network connection is represented by an file descriptor noted by an integer; while, dealing with integers is not convenient for the most cases. Each file descriptor should be added into a event set for kernel to inspect. Serveral CRUD methods to wrap a file descriptor are hereby defined in this module:
// this should be an interface exposed to outside.
struct grpc_endpoint_vtable {
}
// https://github.com/grpc/grpc/blob/master/src/core/lib/iomgr/endpoint.h
// You should pay attention to the methods pointers, which means that implementation is determined at runtime.
void grpc_endpoint_read(Context *ctx, EndPoint *ep)
void grpc_endpoint_write(Context *ctx, EndPoint *ep)
void grpc_endpoint_shutdown(Context *ctx, EndPoint *ep, Error *why)
void grpc_endpoint_destroy(Context *ctx, EndPoint *ep)
// poll set might not be accurate, because epoll is exclusively for Linux system; In MacOS, we use kqueue.
// hence "grpc_endpoint_add_to_eventset" might be better!
void grpc_endpoint_add_to_pollset(Context *ctx, EndPoint *ep, EventPool *epl)
void grpc_resource_user *grpc_endpoint_get_resource_user(EndPoint *ep)
struct grpc_endpoint {
const grpc_endpoint_vtable *vtable;
};
At this point, you might not well be understood what all those mean. Because the module defines an interface grpc_endpiont_vtable, and that table provides runtime implementation of those methods.
Their implementation is considered at runtime. By inspecting “pollset_*nix” and “exec_ctx” (they are keywords from dynamic methods arguments) relavant files, we can get hints on how they are implemented.
If the “endpoint” reporesents a “tcp” connection, a endpoint is created by accepting a socket:
// https://github.com/grpc/grpc/blob/master/src/core/lib/iomgr/tcp_posix.cc, L729 ~ 798
grpc_endpoint *grpc_tcp_create(grpc_exec_ctx *exec_ctx, grpc_fd *em_fd,
const grpc_channel_args *channel_args,
const char *peer_string) {
int tcp_read_chunk_size = GRPC_TCP_DEFAULT_READ_SLICE_SIZE;
...
tcp_read_chunk_size = GPR_CLAMP(tcp_read_chunk_size, tcp_min_read_chunk_size,
tcp_max_read_chunk_size);
grpc_tcp *tcp = (grpc_tcp *)gpr_malloc(sizeof(grpc_tcp));
tcp->base.vtable = &vtable;
...
return &tcp->base;
}
Perhaps we wonder what if the endpoint reprents a pipe? gRPC doesn’t show how to do it but a typical usage is naive. A server programme (whatever langauge you use) reads data in a forever loop from a subprocess’ PIPE. And client programme always “flush” data away off the buffer.
#!/usr/bin/python
# -*- coding: utf-8 -*-
'''
Created on 21 May, 2015
@author: wangyi
'''
import subprocess, threading
import sys, os
# files path config
pwd = os.path.dirname( os.path.realpath(__file__) )
# this will be used for unicode processing
# with python 3 support
# try:
# from urllib import parse
# except ImportError:
# import urlparse as parse
from urllib import urlencode
# this acts as the middleware for process to execute the command
class Session(subprocess.Popen):
def __init__(self, *args, **kwargs):
subprocess.Popen.__init__(self, *args, **kwargs)
def read(self):
for line in iter(self.stdout.readline, b""):
sys.stdout.write(line.decode('utf-8')); sys.stdout.flush();
# for live resposne processing
yield line#.decode('utf-8')
class Browser2(object):
def __init__(self, client):
self.args = ["/usr/local/bin/phantomjs", pwd +"/js/" + client + '.js']
# url + data + mehtod
# *args may contain post body: string 1('q=x'), sgtring 2('q=y')
def view(self, url='', tar='', method='GET', *args, **kwargs):
command = [arg for arg in self.args]
# check out urllib.parse module for 'percent-encoded' string
# in python 2, there is 'safe', 'encoding', 'errors' declaration
# in python 3, this is merged into urllib.parse
query = urlencode(kwargs)
if method == 'GET':
url = url + '?' + query
command.extend([url, tar])
# initiate an session object, which is a wrapper upon pipe instance
session = self.setup(command)
# do something with process
# e.g
for line in session.read():
if line.count('_end_downloading') == 1:
# session.kill()
# this work the process terminated immediately
# session.kill()
# this doesn't work
# this mothod is not recommanded by PEP
session.stdin.write('1\n')
# shoudl use flush other wise the process will block
session.stdin.flush()
# this work but I have to wait until the last minute
# [child_stdout, child_stderr] = session.communicate(input="1\n")
# print(child_stdout)
def setup(self, command, bufsize=1024):
if command is None:
raise Exception("no commands is not allowed.")
return Session(command, bufsize=bufsize, shell=False,
stdin=subprocess.PIPE, stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
Then you can wrote c programme to process data and foward it to your prefered backend. This is the trick I used since 2015.
#include <signal.h>
subprocess(nt argc, char **argv)
{
FILE* buf; // or robust cached io in Linux
char* fmt;
signal(SIGINT, quit_cb); // trap ctrl-c call
LOOP_START
...
fprintf(buf, fmt, data) // I don't like std::cout in c++, sometimes I use boost::format; sometimes I use standard c I/O api.
fflush(buf)
...
LOOP_END
}
Endpoint pair creates client-server endpoints pair. Let me explain how it works. In endpoint_pair_{system}.cc, there are two methods. Named as “create_sockets” to create two sockets followed by “grpc_tcp_create” to create endpoints pair. In common sensen, one endpoint for reading data, andother is for writing. For example:
in Linux,
// https://github.com/grpc/grpc/blob/master/src/core/lib/iomgr/endpoint_pair_posix.cc, L39 ~ 48
static void create_sockets(int sv[2]) {
...
grpc_create_socketpair_if_unix(sv);
...
}
// https://github.com/grpc/grpc/blob/master/src/core/lib/iomgr/unix_sockets_posix.cc, L35 ~ 37
void grpc_create_socketpair_if_unix(int sv[2]) {
GPR_ASSERT(socketpair(AF_UNIX, SOCK_STREAM, 0, sv) == 0); // "socketpair" is defined Linux
}
while in windows[NET, posix protable ],
// https://github.com/grpc/grpc/blob/master/src/core/lib/iomgr/endpoint_pair_windows.cc, L33 ~ 68
#include "src/core/lib/iomgr/socket_windows.h"
...
static void create_sockets(SOCKET sv[2]) {
SOCKET svr_sock = INVALID_SOCKET;
SOCKET lst_sock = INVALID_SOCKET;
SOCKET cli_sock = INVALID_SOCKET;
SOCKADDR_IN addr;
int addr_len = sizeof(addr);
lst_sock = WSASocket(AF_INET, SOCK_STREAM, IPPROTO_TCP, NULL, 0,
WSA_FLAG_OVERLAPPED);
GPR_ASSERT(lst_sock != INVALID_SOCKET);
memset(&addr, 0, sizeof(addr));
addr.sin_addr.s_addr = htonl(INADDR_LOOPBACK);
addr.sin_family = AF_INET;
GPR_ASSERT(bind(lst_sock, (struct sockaddr *)&addr, sizeof(addr)) !=
SOCKET_ERROR);
GPR_ASSERT(listen(lst_sock, SOMAXCONN) != SOCKET_ERROR);
GPR_ASSERT(getsockname(lst_sock, (struct sockaddr *)&addr, &addr_len) !=
SOCKET_ERROR);
cli_sock = WSASocket(AF_INET, SOCK_STREAM, IPPROTO_TCP, NULL, 0,
WSA_FLAG_OVERLAPPED);
GPR_ASSERT(cli_sock != INVALID_SOCKET);
GPR_ASSERT(WSAConnect(cli_sock, (struct sockaddr *)&addr, addr_len, NULL,
NULL, NULL, NULL) == 0);
svr_sock = accept(lst_sock, (struct sockaddr *)&addr, &addr_len);
GPR_ASSERT(svr_sock != INVALID_SOCKET);
closesocket(lst_sock);
grpc_tcp_prepare_socket(cli_sock);
grpc_tcp_prepare_socket(svr_sock);
sv[1] = cli_sock;
sv[0] = svr_sock;
}
pollset, event
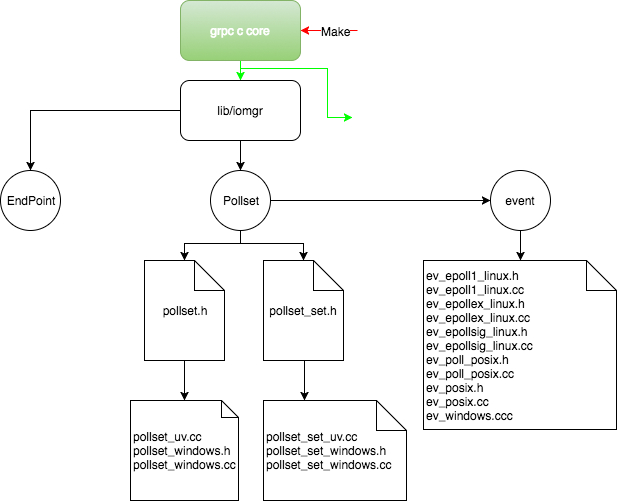
Pollsets means a set of events to be inspected. Since different systems own different solutions of events concurrency, pollset is an interface should be implemented by different systems. Google illustrates “epoll” based implementation of “pollsets” in gRPC. Here is the explanation from gRPC docs:
Each time epoll set is set, kernel will notify application codes that there is an I/O file descriptor ready. The file descriptor might refer to the endpoint in the last section. The endpoint then needs to perform some actions in a thread. This is definition of event.
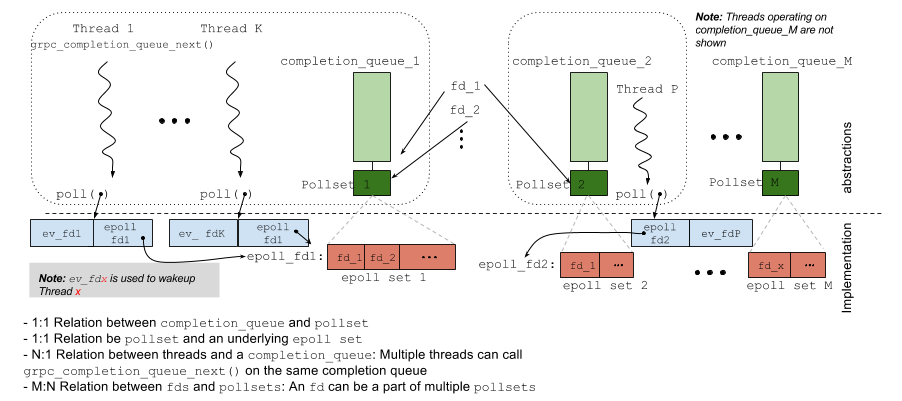
The core of algorithm is to make sure only one thread woke up to process event. This happens after “completion_queue_next_plunk” fired because in user side, event is polled by coding “compeltion queue”. Directly using epoll is not convenient in some situation, we hence need some concepts or abstraction:
- event set: one epoll set -> one pollset
- event operations upon wrapped fd interface
- event dispatching main loop, completion queue.
Our first abstraction is “grpc_fd” which holds “epoll_fd” (epfd) and fd itself points to. It is very unpleasant that implementation in ev_eopll{suffix}_linux.cc is out of different programmers at least this is true for me.
Here comes “grpc_pollset”.
For example, in ev_epollsig_linux.cc, it could be
// https://github.com/grpc/grpc/blob/master/src/core/lib/iomgr/ev_epollsig_linux.cc, L207 ~ 229
/*******************************************************************************
* Pollset Declarations
*/
struct pollset_worker {
/* Thread id of this worker */
pthread_t pt_id;
/* Used to prevent a worker from getting kicked multiple times */
gpr_atm is_kicked;
struct pollset_worker *next;
struct pollset_worker *prev;
};
// this varies in different implementation
struct pollset {
poll_obj po; // contains "polling_obj_type" and a "mutex" instance, you can regard it as "polling_island" from docs
...
pollset_worker root_worker;
...
};
However, when looking at ev_epoll1_linux.cc, times changes:
// https://github.com/grpc/grpc/blob/master/src/core/lib/iomgr/ev_epollex_linux.cc, L190 ~ 213
struct pollset_worker {
bool kicked;
...
pollset_worker_link links[POLLSET_WORKER_LINK_COUNT];
...
};
#define MAX_EPOLL_EVENTS 100
#define MAX_EPOLL_EVENTS_HANDLED_EACH_POLL_CALL 5
struct pollset {
pollable pollable_obj; // contains "polling_obj_type" and a "mutex" instance
...
PollsetWorker *root_worker;
...
struct epoll_event events[MAX_EPOLL_EVENTS];
};
It seems that they are decribing worker and pollset. We know that each job must be processed stand alone by some thread. There must have something related to threads. The fact is that the bunch of codes just try to wake up a thread. To understand it well, we can see how thread pool is implemented in c langauge.
//
// thread_poll.cpp
// SimpleHTTPServer
//
// Created by Wang Yi on 4/10/17.
// Copyright © 2017 Wang Lei. All rights reserved.
//
#include "threading_api.h"
// #include "queue.h"
struct _thread;
struct _job;
typdef void* (*func)(void*);
typdef static void* (*loop)(thread* self);
typdef void (*init)(thread* self);
struct _job_links {
struct _job *pre;
struct _job *next;
} job_links;
typdef struct _thread {
pthread_t tid;
thread_pool *thpool
} thread;
typdef struct _thread_pool {
thread threads[N];
// other statistic info
...
} thread_pool;
typdef struct _job {
void *args;
func cb;
job_links;
queue q;
} job;
So we have some worker with query links. and threads queue. Simple searching shows that grpc core does not define that and leave the code to application layer. So what realy happened to grpc C core? In epoll wrapped by “grpc_pollset”, empirical approaches (see sumbitted patches) implies that, the actual polling code structure should be:
do {
ev_rc = epoll_wait(epoll_fd, ready_events, RPC_EPOLL_MAX_EVENTS, timeout_ms, sig_mask)
if (ev_rv less than 0){
// check linux signal errno or report error immediately
}
// linear scan. Different from "select" or "poll", this actually is O(1) operation
// bla bla bla
} while (some_condition_to_exit)
This will called inisde so called compeltion queue. Latest gRPC implementation separates the loop in several parts to hook callbacks. But it doesn’t matter. Let us foucs on implementation in “ev_epollsig_linx.cc” because the others are similar:
- main event loop
- per event loop operation
- worker has already pushed into front of the pollset. you don’t need to worry about it.
...
#include <epoll.h>
#include <pthread.h>
// L176 ~ 205
struct polling_island; // wraps an "epoll" instance fd created by "epoll_create1"; the fd is exactly target what "epoll_wait" inspect with.
// epoll main loop operation, ev_epollsig_linux.c L1273 ~ 1292
static void pollset_work_and_unlock(Context *ctx, pollset *pollset, Worker *workers, ...)
{
...
ep_rv =
epoll_pwait(epoll_fd, ep_ev, GRPC_EPOLL_MAX_EVENTS, timeout_ms, sig_mask);
if (ep_rv < 0) { ... }
...
for (int i = 0; i < ep_rv; ++i) {
...
// calling grpc_lfev_set_ready(exec_ctx, &fd->closure, "eventName") inside, which defined in "lockfree_event.h"
}
}
grpc_lfev_set_ready are what job dispatching codes are, notifying a thread to process a job. We will be back to it in section “scheduler, completion queue and thread model”. Line 332 ~ 375 defines the method “polling_island_add_fds_locked” to add file descriptors(fds) into epoll instance. If the associated reference reaches the maxium capacity allocated, grpc reallocs memory to hold newly added fds.
Other CURD methods accocaited with epoll instance defined in Line 332 ~ 553.(pay attention to the version I am analyzing!) followed by “polling_island_merge” defined in L651 ~ 683.
// https://github.com/grpc/grpc/blob/master/src/core/lib/iomgr/ev_epollsig_linux.h, L29
const grpc_event_engine_vtable *grpc_init_epollsig_linux(bool explicit_request);
// https://github.com/grpc/grpc/blob/master/src/core/lib/iomgr/ev_epollsig_linux.cc,
When multi threading introduced into the currency technology, we have to deal with “raceing conditions”. We roughly have three methods to deal with that bad conditions: (from popular best sellers):
- Duplicating data in each threads by mapping them into heap in User Space. For example, all the data in a thread safe FIFO queue, will be copied into heap space.
- Adding logics controls using something like “Mutex” upon data being processed to define accessing order of time critical portion of programmes.
- Thread Local Variable (TLS) technology in time critical programme
Method 1, means more memory, less expensive synchronization. While method 2, means less memory, and more expensive synchronization. For the most cases, we pursue the frist solution. Method 3 is an alternative solution to method 1. in linux system you can do this by:
static __thread {var_type} {var_name}
which means the variable is local to thread for reuse.
Intel’s “Intel Guide for Developing Multithreaded Applications” explainned why TLS can effectively reduce synchronization in a time critical portion of programme.
Intel also illustrates that terminology in “OpenMP” and concludes that data in TLS lives longer in a processor’s cache than shared data, if the processors do not share a data cache.
In gRPC, shared memory will be taken care by “atomic” operations. Let see some example first, and more details will be discussed in section “multithreaded atmoic operations”. When you read the codes below, just pay attention to the meaning of the codes: to execute a callback in some thread. We will work on details step by step. Polling happens inside “pollset_work” in grpc
// https://github.com/grpc/grpc/blob/master/src/core/lib/iomgr/ev_epollsig_linux.cc, L1298 ~ 1399
// as far as I am concerned, this function should be executed in some thread scheduled by poller's scheduler.
// this method appreas in several implementation.
static Error* pollset_work(Conext *ctx, Pollset *pollset, PollsetWorker **worker, time deadline)
{
Pollset_Worker _worker;
// SET UP
_worker.pt_id = pthread_self();
if (worker) *worker = &_worker;
// set thread local storage using grpc TLS api
if (con1) {
} else if (con2) {
...
push_front_worker(pollerset, &worker);
pollset_work_and_unlock(exec_ctx, pollset, &worker, ...); // !important, in Windows there is a similar implementation of asynchroneous IO in pollset_windows.cc. Instead of calling "pollset_work_and_unlock"
exet_ctx_flush(exec_ctx);
reaquire_Lock(&pollset->po.mu);
remove_worker(pollset, &worker);
}
// CLEAN UP
...
return error;
}
Pollset_set is just a container of pollset. Polling any pollset in pollset_set will result in polling the central polling_island, as a result of which only one thread woke up to complete the task. When sever wants to aquire an event, this method will be called inside “grpc_completion_queue_next(CompletionQueue *cq, …)”.
channel
We already have concept “Endpoint”, so what is “channel” why it is useful? A client might has several communication channels, to send message to host on different ports. Before we talk about more it, let us dive into golang “channel”. Golang network together with python are two very important technologies for “C” system programmers.
In golang, an asynchronous channel (buffered) defined in runtime works like[2]:
// https://github.com/golang/go/blob/master/src/runtime/chan.go, in rumtime package
// You don't need to see any segment of codes in net package because they do nothing with underlying network.
// There is also a pure C implementation by [Tyler Treat](https://github.com/tylertreat) transplanted from go code base roughly arround 2 years ago.
//
// Created by Wang Yi on 12/10/17.
// Copyright © 2017 Wang Lei. All rights reserved.
//
package example
import (
"fmt"
)
func read(ch chan string) {
fmt.Println("Reading ...")
var buf string
fmt.Scanf("%s", &buf)
// send message
ch <- buf // >
}
func main()
{
// blocking channel
ch = make(chan string, 10)
go read(ch)
// ch <- "first" // ></->
select {
// the reciever blocks until a sender is ready
// in this situation, the channel is empty hence the the sender is not ready. it blocks
case msg := <-ch: // ></-ch:>
fmt.Println(Response(msg))
}
}
Another example:
// mimick the pure C channel example developed by Tyler Treat
//
// Created by Wang Yi on 12/10/17.
// Copyright © 2017 Wang Lei. All rights reserved.
//
package main
import "fmt"
const N = 5
func read(ch chan string, done chan bool) {
fmt.Println("Reading ...")
for {
msg, ok := <-ch // ></-ch>
if !ok {
fmt.Println("No more messages in ch\n")
fmt.Println("send ready sig into done channel ...")
done <- true // ></->
fmt.Println("done channel is ready.")
return
}
fmt.Println("Received:", msg)
}
}
func main() {
fmt.Printf("hello, world\n")
ch := make(chan string, N)
done := make(chan bool)
// ch <- "first" // >
go read(ch, done)
for i := 1; i < N; i++ {
ch <- fmt.Sprintf("<msg %d>", i) // >
fmt.Println("send msg ", i)
}
close(ch)
<-done // ></-done>
fmt.Println("All the msgs passed down.")
}
The output might look like that go routine is blockedb by main routine.
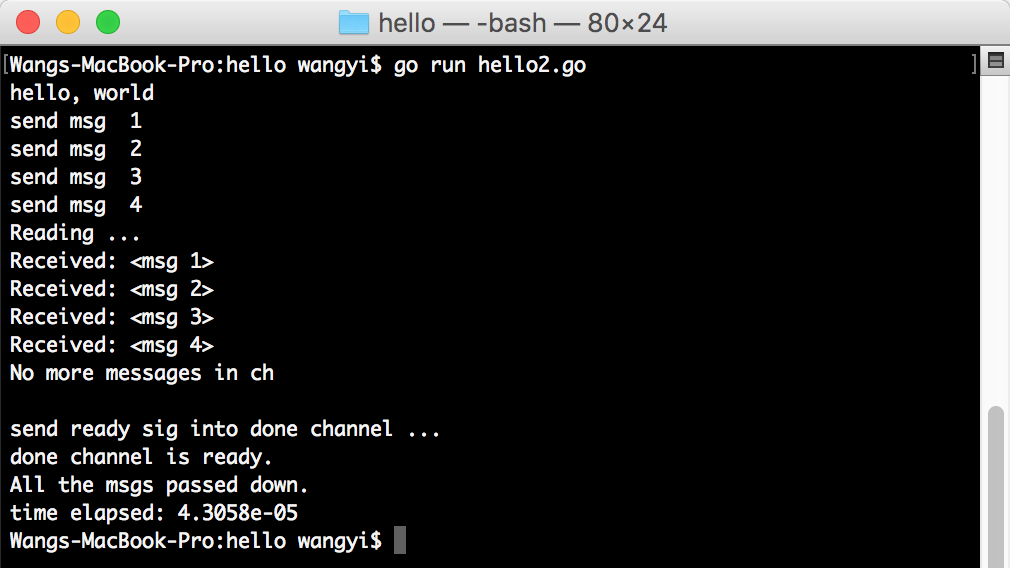
If you use unbuffed channel instead, the programme becomes slow while go routine will be blocked.
...
ch := make(chan string)
...
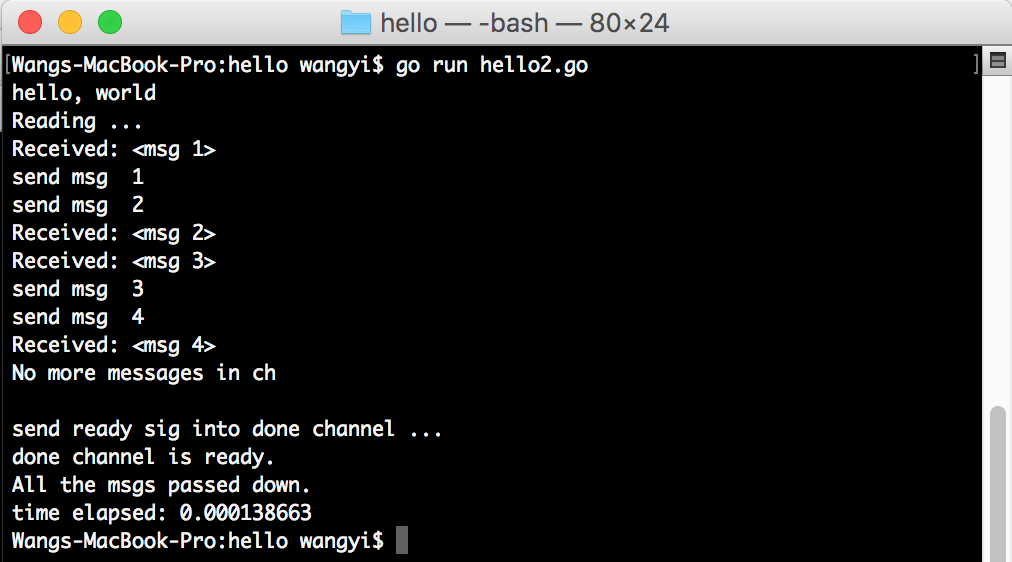
We conclude that channel in go is a message queue through wich messages are passed by it. The interesting part in this demo is that channel can be used to notify completion of tasks. More examples in terms of grpc C core will be added later.
execution context
schedualer, completion queue and thread model
Pointed by Kuchibhotla[4], grpc library consumes threads created by server application like c++, python, go and so on so forth. For example in c++, thread pool is defined in src/cpp/thread_manager.h. Usually a default thread pool will be created after a server boots up in a machine.
It is intersting that gRPC gives birth to thread pool additional inbuilt ability to creates threads on demand. They called that “ThreadManager”,
In c programme a grpc server created by following codes:
// see test/core/fling/server.c
#include <grpc/grpc.h>
#include <signal.h>
static grpc_completion_queue *cq;
static grpc_server *server;
int server(int argc, char **argv) {
grpc_event ev;
...
server = grpc_server_create(NULL, NULL)
grpc_server_register_completion_queue(server, cq, NULL);
grpc_server_start(server);
// register signals
signal(SIG{X}, sig{lower_case(X)}_handler);
...
While (true) {
...
ev = grpc_completion_queue_next(cq, ...)
handle(ev);
...
}
// CLEAN UP
DONE:
BLA BLA BLA
}
In gRPC v1.6.3, all the polling methods will be dynamically assigned into completion queue “vtable” interface at runtime. “grpc_completion_queue_next(cq, …)” is implemented by “cq_next”:
// https://github.com/grpc/grpc/blob/master/src/core/lib/surface/completion_queue.cc, L815 ~ 938
// The bunch of codes keep envolving, hence it changes from time to time.
static grpc_event cq_next(grpc_completion_queue *cq, gpr_timespec deadline,
void *reserved) {
grpc_event ret;
cq_next_data *cqd = DATA_CQ(cq);
...
grpc_exec_ctx exec_ctx = GRPC_EXEC_CTX_INITIALIZER(0, func, &args);
for (;;) {
...
grpc_cq_completion *_cq_curr = cq_event_queue_pop(&cqd->queue);
if (_cq_curr != NULL) {
ret.type = GRPC_OP_COMPLETE;
ret.success = _cq_curr->next & 1u;
ret.tag = _cq_curr->tag;
_cq_curr->done(&exec_ctx, _cq_curr->done_arg, _cq_curr);
// finish the loop
break;
} else { ... }
...
/* The main polling work happens in grpc_pollset_work */
gpr_mu_lock(cq->mu);
cq->num_polls++;
grpc_error *err = cq->poller_vtable->work(&exec_ctx, cq->pollset, NULL, iteration_deadline);
gpr_mu_unlock(cq->mu);
...
}
if (cq_event_queue_num_items(&cqd->queue) > 0 &&
gpr_atm_acq_load(&cqd->pending_events) > 0) {
gpr_mu_lock(cq->mu);
cq->poller_vtable->kick(&exec_ctx, POLLSET_FROM_CQ(cq), NULL);
gpr_mu_unlock(cq->mu);
}
// CLEARN UP
...
return ret;
}
multithreaded atmoic operations
Some atomic operations are defined in “grpc/impl/codegen/atm.h”. It varies from one platform to anther. In GCC platform, for example:
// https://github.com/grpc/grpc/blob/master/include/grpc/impl/codegen/atm_gcc_atomic.h
typdef intptr_t gpr_atm;
others are assebled by operations aquiring a lock and ones releasing a lock.
gRPC uses “combiner” to run time critical codes in multi threads envrinonment. A tipical grpc operation is of the form:
gpr_mu_unlock(&lock);
exec_ctx_{method}(exec_ctx);
gpr_mu_Lock(&lock);
We can do better by learning some experiences from other virtual machine langauge : “decorator” or “proxier”. We can bypass some targets methods into an object where they are combined together.
def combiner(self, *fn_args_list):
def wrapper(*args, **kw):
aquire(self.lock)
for fn, args in fn_args_list:
ret, ok = fn(args)
release(self.lock)
return ret, ok
return wrapper
Multiple Services Architecture
Pending …
Naming Service
Load Balancing
Heart beating & Service discover
Authorization & Authentication
SSL and HTTP2 streaming connection
Usage Senario
There are already too much grpc usage tutorial arround internet which has a deal with protobuf to define servercies. To summerize for content complete, gprc first creates a server then starts threads pool by calling “”.
Summary
THIS WILL BE PROVIDED AFTER FULL COVERAGE OF TESTS IN CLOUD PROVIDER.
Bibliography
- J.Silcock and A.Goscinski, School of Computing and Mathematics, Deakin University Geelong, Australia
- Golang, https://en.wikipedia.org/wiki/Go_(programming_language)
- Scheduling Multithreaded Computations by Work Stealing, Robert D. Blumofe and Charles E. Leiserson, 1999 ACM 0004-5411/99/0900-0720
- grpc docs, https://grpc.io/grpc/cpp/md_doc_epoll-polling-engine.html
- gprc docs, https://grpc.io/grpc/core/index.html